认识智能语音呼叫系统

认识智能语音呼叫系统
ivansli1. 什么是智能语音系统
现实生活中,会遇到下面一些场景:
1.对着iPhone说”hey, siri”
2.对着智能音响说”天猫精灵”,”小爱同学”,”小度小度”
3.对着导航说””要到XXX,请帮我规划路线”
4.接到阿里云打来的服务报警电话
5.接到银行、通讯服务商、电商平台的推销电话
6.机器人在线客服
…

对于上面的场景,不知道你遇到过或用过多少。他们有一个共同的特点:人机交互;他们有一个通用的叫法:智能语音系统。
说起智能语音系统,很多人可能第一次听说。不理解没关系,在这里跟随我的步伐一起来看看这是个什么东西。
如果对 智能语音系统 这个专业名词进行拆解,大概可以拆分为三个词:智能:使用AI、机器学习来识别交互过程中的意图,从而做出正确的决策
智能的终极目标也是图灵测试的终极目标,让机器更像人或者比人更像人
语音:文本转语音(TTS),语音转文本(STT)这两个相反的过程
文本转语音相当于一个说的过程,相当于嘴巴
语音转文本相当于一个听的过程,相当于耳朵
人类在日常的交互过程中,说与听一般如下:说的过程是人的大脑中产生一些想法,想法汇总为表意词汇,词汇通过嘴巴念出来,引起空气振动,从而产生声音听的过程是空气振动产生的声音进入耳朵带动鼓膜振动,鼓膜振动产生电信号传入大脑,电脑根据电信号识别意图
系统:专门用来处理特定领域的软件或者SaaS服务,有时候也称之为机器人程序。
软件或者SaaS服务的区别在于:
软件 一般是某些公司内部专用的服务,不对外
SaaS服务 一般是某些公司开发的服务,不仅自己可以用,其他公司也可以付费使用
那么,什么是智能语音系统呢?
可以总结为:通过AI来识别与人类交互过程中的意图从而做出正确决策的软件。
2. 智能语音系统的分类
对于 智能语音系统 来说,根据人机交互的逻辑一般可以分为两类:
1.call in
2.call out
怎么理解呢?
因为这里探讨的是一套软件系统,那么咱们就是站在软件系统的角度来看问题。
系统主动呼叫出去叫 call out,系统被动接入外部的呼入叫 call in。
接到机器人给你打的电话,对机器人来说就是 call out。类比 阿里云服务报警电话、电商推销电话等
机器人接到外部人类打进来的电话,对机器人来说就是 call in。类比 电信运营商的客服系统等
call out与call in除了主动与被动的区别,对于系统来说还有一个关键的区别就是:call out 在机器人呼出去之前可以提前准备需要的音频等内容,对实时性要求不太高,可以在没有任务时关机。call in 在机器人接收到呼入的电话后,需要实时的生成音频等内容,对实时性要求高,一般是7x24小时,不能关机。
3. 智能语音系统部分相关术语
TTS
文本转语音
STT (ASR)
音频转文字
VAD
识别用户说话的开始与结束
NLU
主要解决意图分类问题
VoIP
主要解决软件服务与电话网络交换数据的问题
4. 智能语音呼叫系统的常见架构
对于提供 智能语音系统 的公司,一般都会根据情况定制一些功能。但是抽象出来大体相似,这里以call out为例描绘其架构,大致如下:
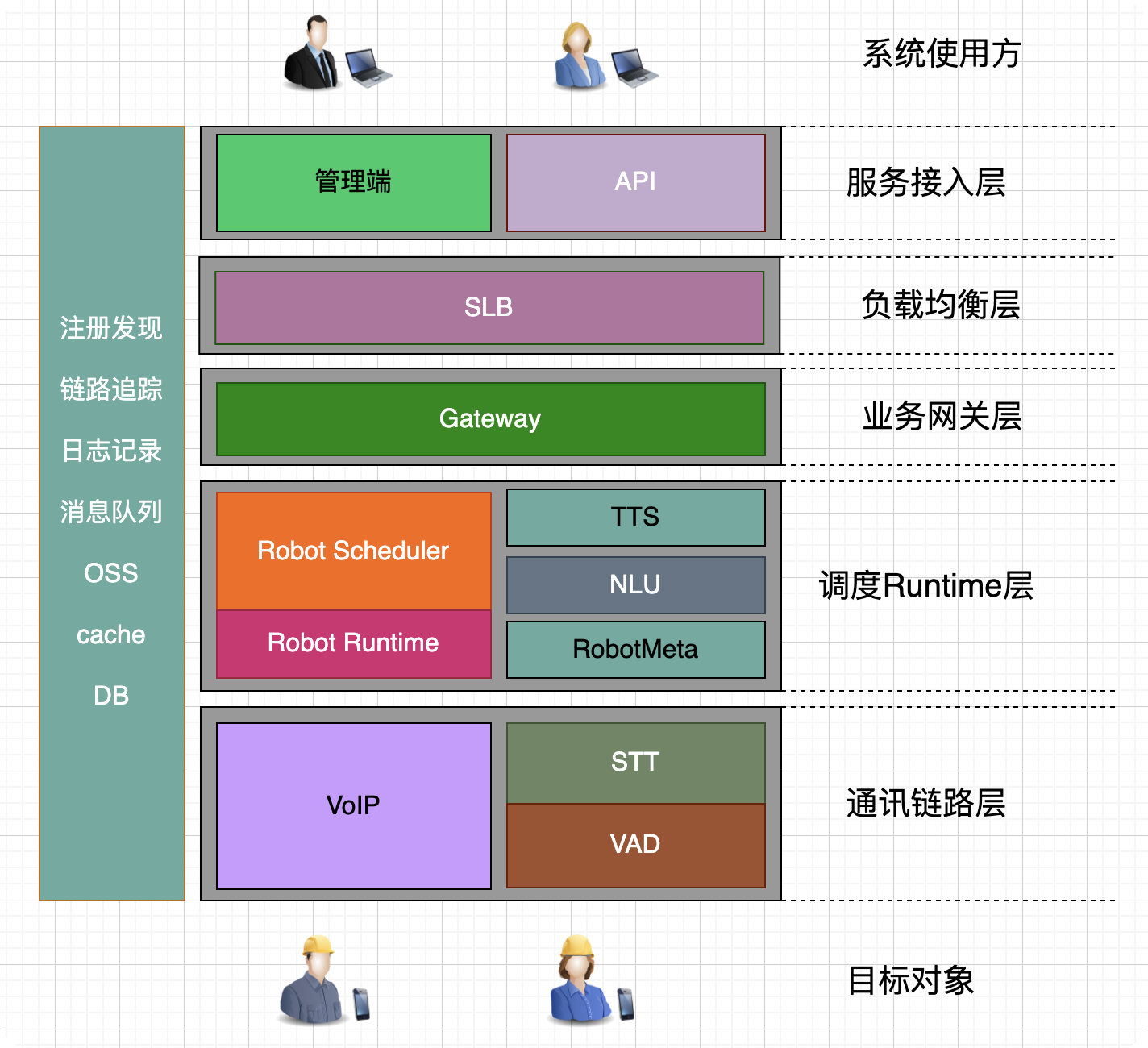
架构分层分为若干层,分别是:
1.系统使用方
使用方会提供电话号码给系统来进行拨打呼叫
2.服务接入层
提供给外部使用的管理端或者api接口 等
3.负载均衡层
对外部请求进行转发(TCP/IP协议的第4层或者第7层)
4.业务网关层
鉴权、限流/熔断/降级 等
5.调度Runtime层
用于在进行语音呼叫之前准备需要的音频等文件,准备好之后把呼叫任务投递到MQ中供调度RuntimeScheduler使用。
从 MQ 队列获取呼叫任务,每个任务对应一个机器人。同时对语音呼叫机器人调度派发、机器人呼叫中的流程管控等
6.通讯链路层
使用电信运营商提供的线路以及号码进行呼叫链路的创建、音频上传、音频识别等
7.目标对象
电话接听人,一般都是业务使用方提供的电话号码等
5. 智能语音呼叫系统call out的交互过程
对于整个交互过程是 音频/文本 数据流动的过程,也是架构中各个 组件/服务 间的交互过程,其交互大致如下:
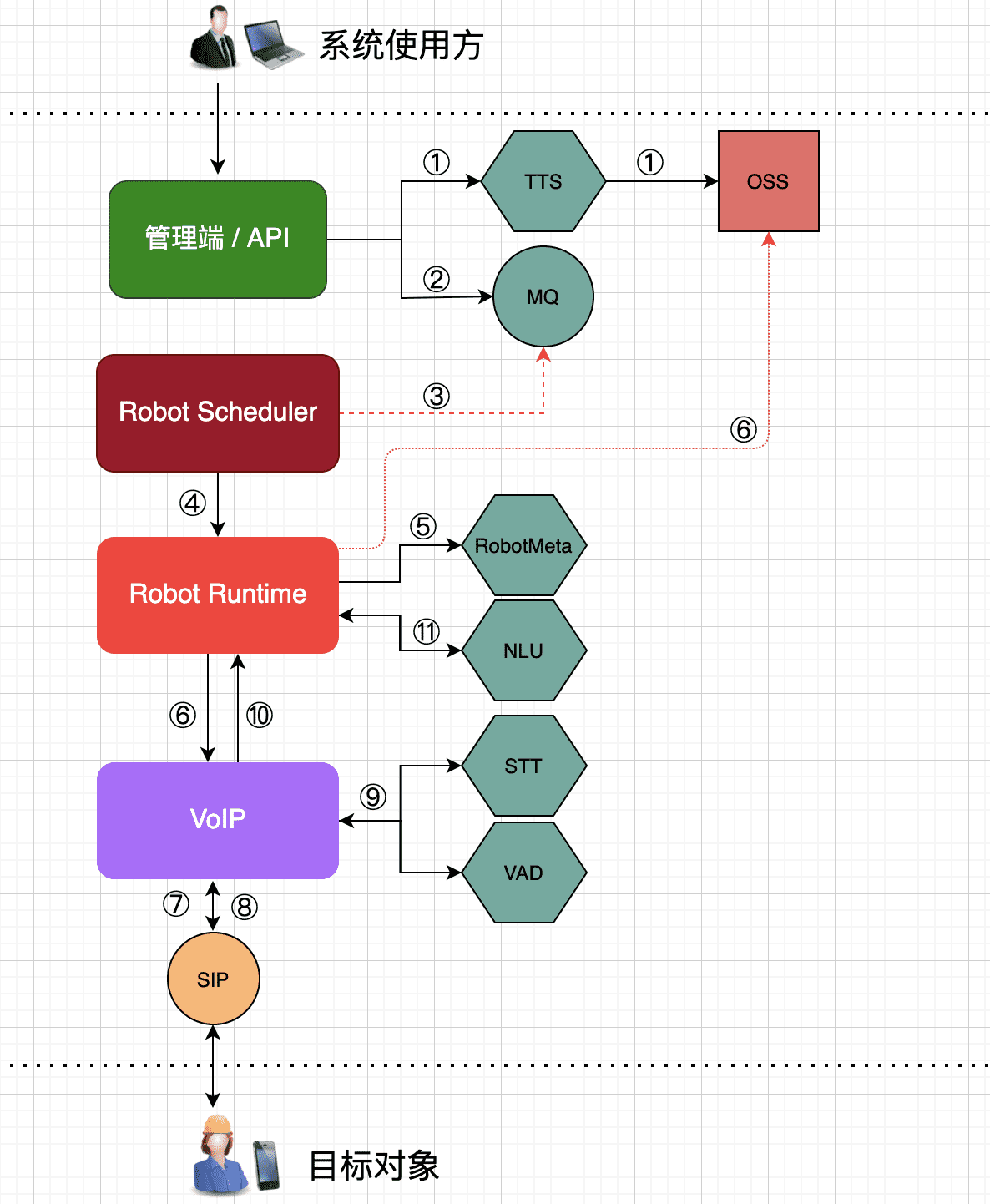
准备条件:
业务适用方通过在后台或API接口创建语音呼叫任务
交互过程:
① 任务创建之后先调用 TTS 服务生成对应的音频文件,并存储到 OSS 服务中
② 把语音呼叫任务存入消息队列
③ Robot调度器 从消息队列获取任务
④ Robot调度器 把呼叫任务按照各种维度下发给不同的Robot运行时,开始准备语音呼叫
⑤ Robot运行时 在呼叫之前,先获取机器人的配置信息
⑥ Robot运行时 调用 VoIP 试图创建呼叫链路
⑦ VoIP 通过 SIP 等相关协议并使用电信运营商提供的号码创建到达目标对象侧的链路
⑧ 目标对象接听电话之后,把目标对象说的内容进行上报
⑨ VoIP 接收到目标对象说话内容之后通过 STT 把说话内容转换成文本
⑩ VoIP 把说话内容对应的音频上报给 Robot运行时
⑪ Robot运行时 把目标对象说话内容对应的文本提交给NLU让其识别用户意图,NLU识别意图之后返回用户意图标识
⑥ Robot运行时 根据用户意图,从 RobotMeta 中提取意图响应标识。根据标识获取对应音频内容给 VoIP,VoIP 播放音频,从而响应目标对象的意图
这里的音频有几种获取方式:
1.步骤① 中生成的存放在 OSS 中的音频。这些音频都是一些特有的内容,每个目标对象都不一样
2.语音呼叫系统通用的音频
3.如果是call in业务,这里需调用 TTS 实时生成响应音频。对实时性要求高,如果指定时间内没有生成,则使用兜底音频 或 断开整个链路
⑦ 播放响应音频内容给目标用户
⑧ 目标对象说的内容进行上报
最终整个交互过程形成一段完整的对话,理想情况下是 机器人说一句,人类说一句,在时间轴上连续交错,如下所示:
实际情况却是非常复杂,因为有可能当前话还说完就会被打断,从而影响当前决策过程,而一个小的决策过程可能会影响整个最终的结果(有点像蝴蝶效应)。但是,优秀的决策机制会在整个决策过程中不断地调整,从而降低某一个小环节对整体的影响。
6. 智能语音系统存在的挑战
表面看整个智能语音系统比较简单,交互比较清晰,但实际上却存在着不少挑战。
这里列出一些存在的挑战:
1.TTS 生成音频的实时性与非实时性
2.Robot Scheduler 的调度需要根据 VoIP的线路使用情况、任务的数量、不同任务的优先级 等因素进行派发
3.Robot Runtime 与下游各个组件之间需要使用长连接进行交互,如果连接被重置或者断开,此通交互需要断开或者重试
4.STT 语音转文本的识别正确率不可能100%,需要不停的针对模型进行优化
5.RobotMeta 中机器人的流程定制过程非常复杂
RobotMeta中配置着一个语音交互机器人的各种信息以及不同话术跳转流程
6.面对不同服务间的延迟问题,该做出合适策略来保证整体可用
7. 智能音箱交互流程
在了解了 智能语音呼叫系统 的交互过程之后,对于常见的智能音箱交互过程,大家应该有了一个属于自己的答案,下图列出智能音箱的call in交互过程。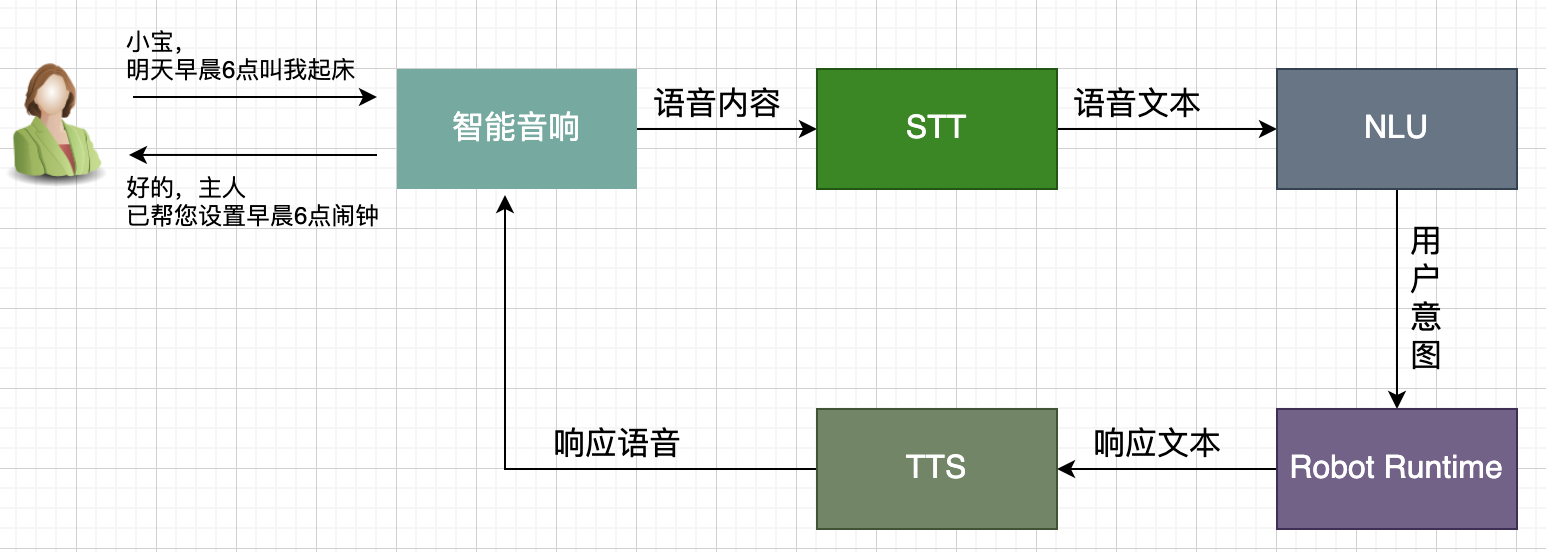
8. 智能语音系统的一些服务供应商
搭建一整套智能语音系统需要若干组件与服务,每一个服务提供不同的功能,如果是全部开发出来,对于小公司来说会有一定的难度与要求。目前,市面上有很多可用的服务供应商,不同规模的公司与业务可以自行选择适合的方式来搭建。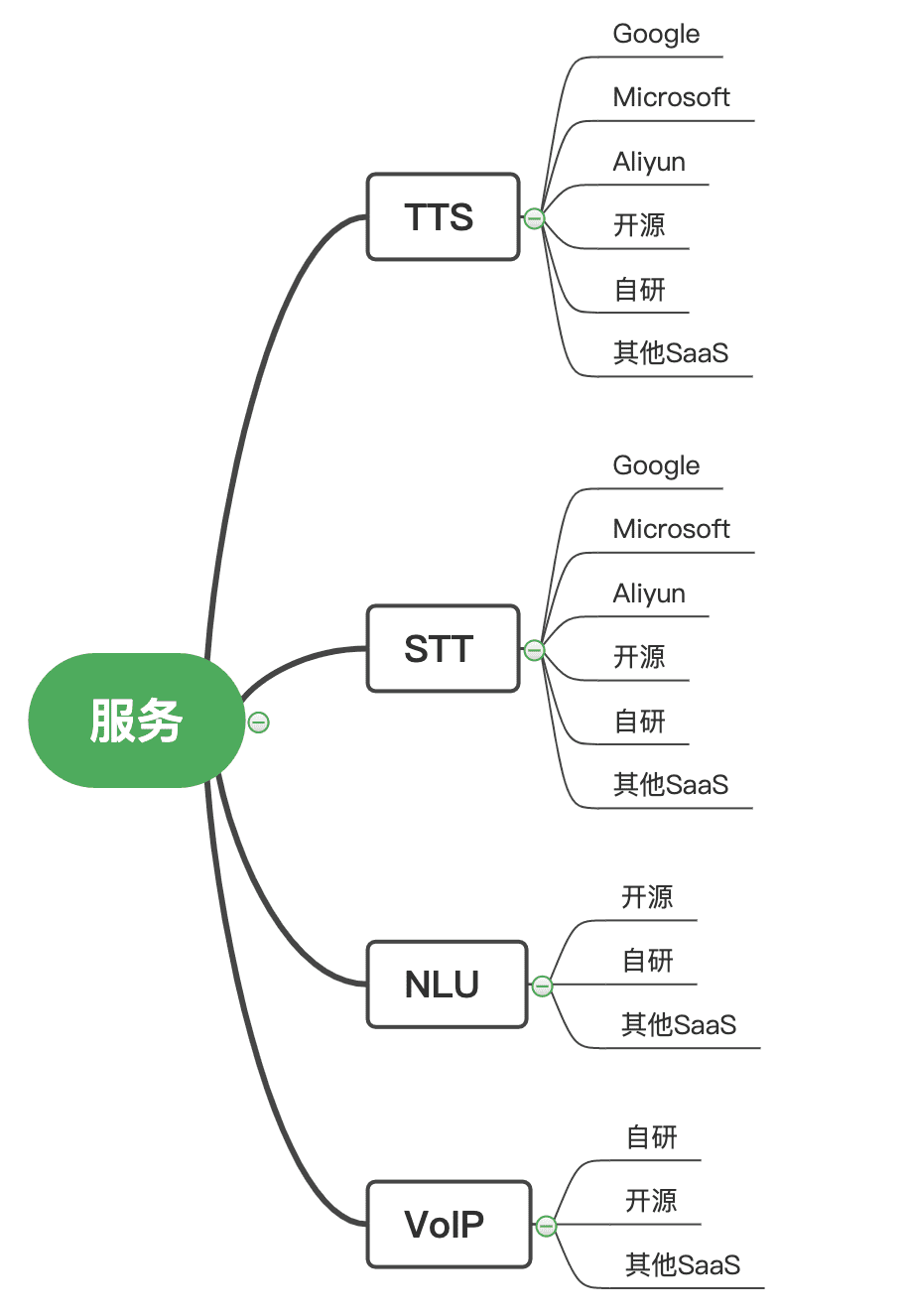
9. 总结
何为智能?何为交互?如何交互?通过阅读本文,对于这些问题会给你一些解答。
随着科技的飞速发展,未来会有更多可交互的智能设备、商用机器人等商品出现。当这些智能设备出现时,怎样能够更好地进行交互,是上述系统要做的事情。但是,对于我们来说如何更好地使用才是最重要的。