分布式ID的5种生成方式以及Go源码中的一种应用

分布式ID的5种生成方式以及Go源码中的一种应用
ivansli关于分布式ID
从目前互联网的系统架构来看,大部分公司为了避免服务节点出现单点故障、保持高可用、高性能等特性,在部署服务时都会部署多个节点,每个节点承担整个服务的一部分请求。对于同一服务多个节点中的每个节点来说,提供的功能相同。节点在处理数据的过程中会根据不同的业务场景,操作相同或不同的数据源。
对于操作相同的数据源,则会形成数据竞争(大部分情况下需要加锁、串行执行)。对于操作不同的数据源,则可以并行/并发处理(无需加锁)。
对于某些场景下的数据资源,需要有全局唯一的数据资源标识。例如:电商系统中的订单ID号、聊天群组中的消息ID号、上传文件到存储系统中之后生成的文件ID号、用户注册系统中的用户ID号、商户系统中的商户ID号、开放平台中的开发者账号ID等等场景。
这些ID号在分布式系统架构中,可以统称为分布式ID。
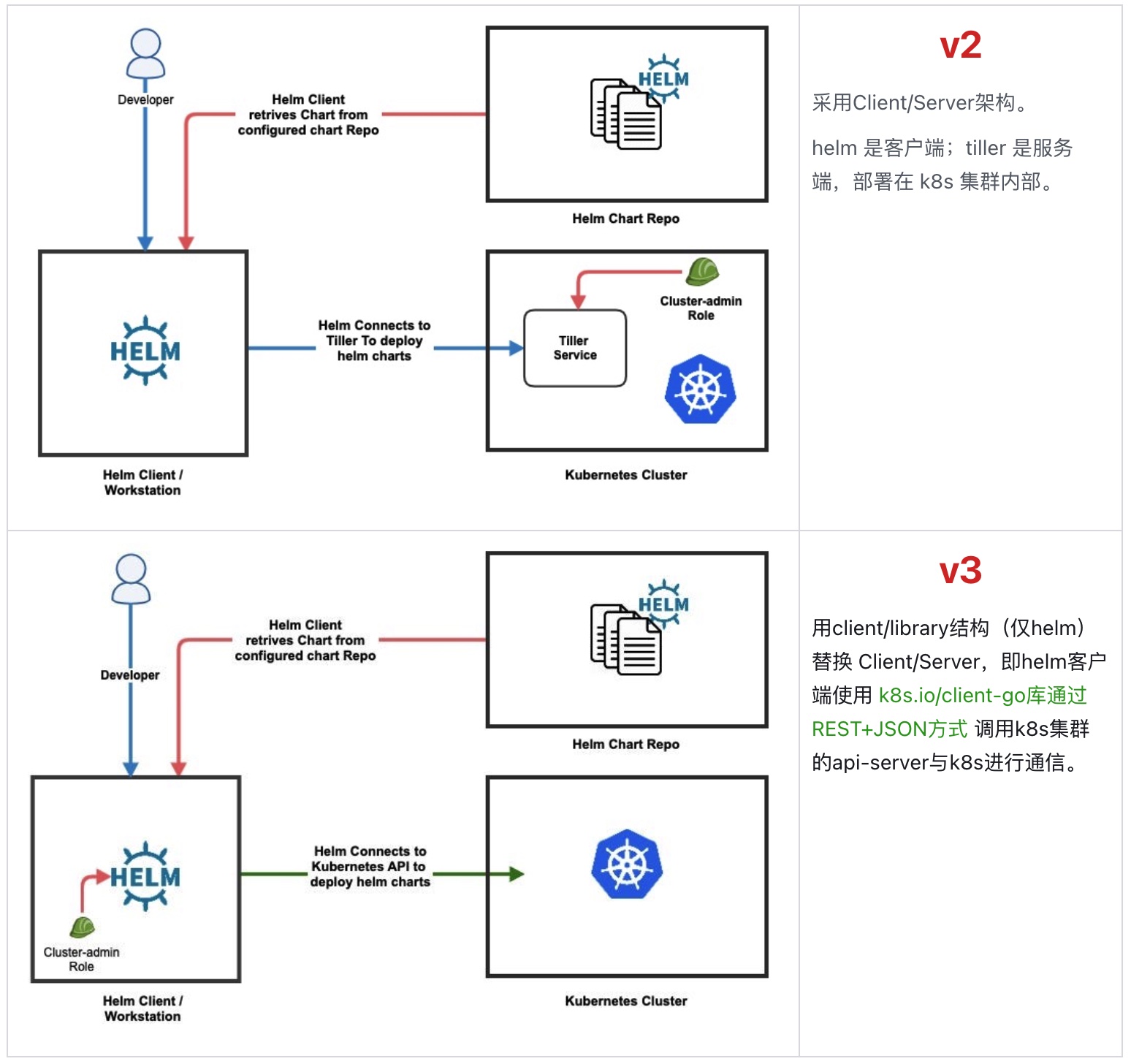
常见的5种分布式ID生成方式
按照是否需要协调(co-ordination)节点,生成分布式ID的方法可以分为2大类:
- 不需要联网,单服务节点可以在本地生成
- 需要联网,依赖协调节点生成
这2大类中又可以细分出来多种具体的实现方式,汇总如下图所示:
UUID
维基百科:通用唯一识别码(Universally Unique Identifier,UUID)用于计算机体系中以识别信息的一个128位标识符。
https://zh.wikipedia.org/wiki/%E9%80%9A%E7%94%A8%E5%94%AF%E4%B8%80%E8%AF%86%E5%88%AB%E7%A0%81
UUID 是由一个16进制下的32位数所构成,故UUID理论上的总数为1632 = 2128,约等于 3.4x1038。就是说若每纳秒(ns)产生1万亿个UUID,要花100亿年才会将所有UUID用完。
在大约100年内每秒生成10亿个UUID后,创建单个重复的概率将达到50%
UUID的标准型式包含32个16进制数字,以连字号分为五段,形式为 8-4-4-4-12 的32个字符。
格式:xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
示例:550e8400-e29b-41d4-a716-446655440000
四位数字 M 表示 UUID 版本,数字 N 的一至三个最高有效位表示 UUID 变体。
标准中定义了五个版本(versions),并且在特定用例中每个版本可能比其他版本更合适(版本由M指示)。
版本1 - UUID 是根据时间和 节点ID(通常是MAC地址)生成;
版本2 - UUID是根据标识符(通常是组或用户ID)、时间和节点ID生成;
版本3、版本5 - 确定性UUID 通过散列(hashing)名字空间(namespace)标识符和名称生成;
版本4 - UUID 使用随机性或伪随机性生成。
以版本4为例,其UUID所有值的空间为 5.3x1036: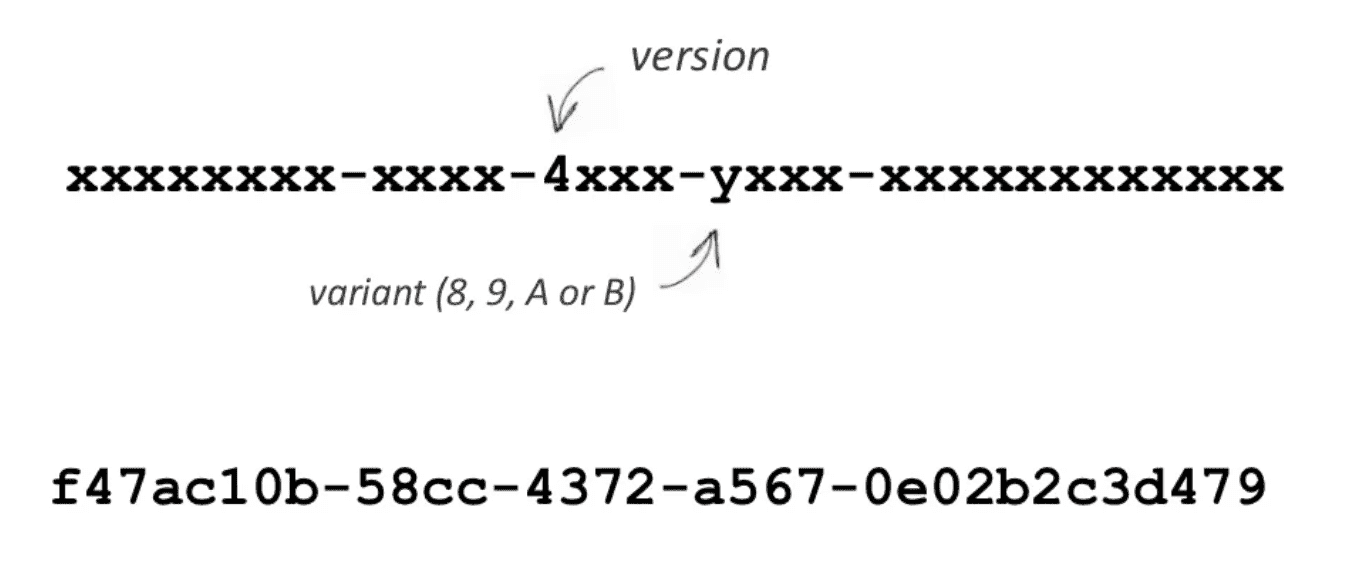
这个值空间有多大呢?
如果从宇宙诞生开始每秒生成一个UUID,则到现在大约共有 1.1x1019。
特点:
- 128 bit
- 生成简单,单节点就可以生成,不依赖协调节点
- IDs 是非数字
- IDs 不会随着时间推移增长
UUID 的变体 ULID(通用唯一词典分类标识符)被视为是一种UUID的替代解决方案。
Twitter snowflake
根据不同的定义,把ID的不同bit位划分为不同的段。
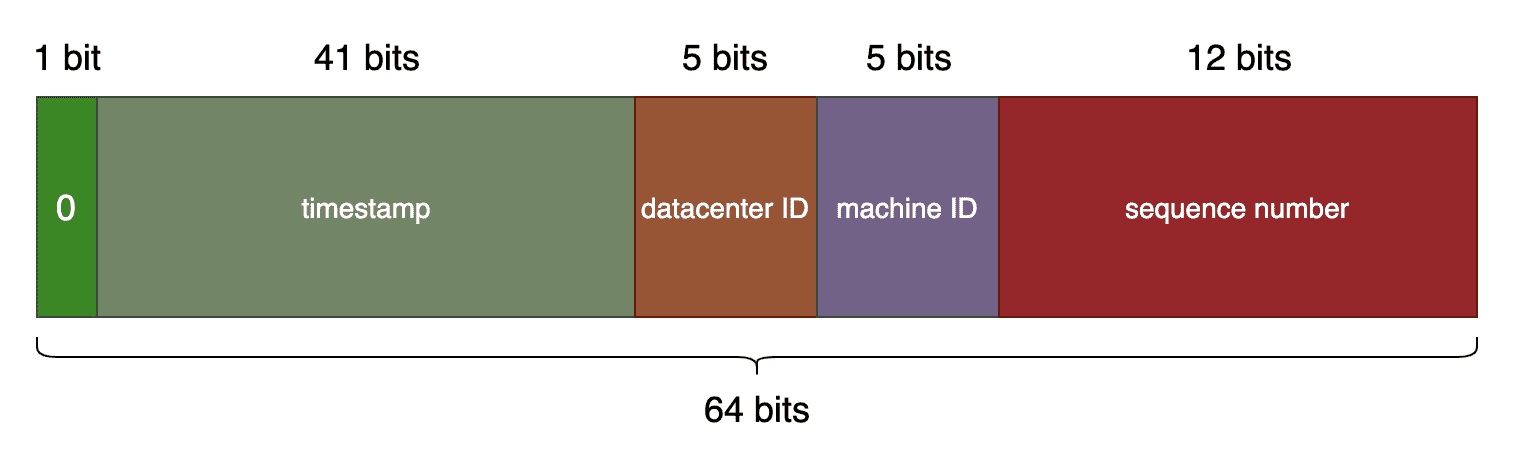
1 bit 保留位
41 bit 时间戳,表示了自选定的时期以来的毫秒数,2^41-1=2199023255551毫秒
2199023255551 ms/1000 seconds/365 days/ 24 hours/3600 seconds,大于可以工作69年。
69年之后(有多少公司能存活69年?),需要新的算法或者技术来处理ID5 bit 数据中心ID,共可容纳 32 个数据中心
5 bit 机器ID,共可容纳 32 个机器ID
数据中心ID+机器ID 如果设置有问题,可能会导致最终生成的ID冲突。一般可以通过环境变量进行设置
12 bit 数字序列号,共有4096种组合。序列号通过进程/机器内部自增1得到,每毫秒重置为0。除非同一毫秒内有多个ID生成,否则为0。
一台机器上每毫秒最多生成4096个新的ID
特点:
- 64 bit
- ID的bit位根据不同含义,划分为5个段
- 生成简单,单节点就可以生成,不依赖协调节点
- 可以是数字(一般是数字),也可以转换为16进制的非数字字符串
从目前来看,市面上不同的公司、不同的编程语言都有参考 snowflake 来开发出相同或相近的实现。有些实现甚至为了获得更大的数值域空间,把64bit扩充为128bit。
Database auto-increment
数据库主键具有天然的自增特性,每次对数据进行操作主键都会自增。但是,由于数据库会频繁的读取操作磁盘数据,所以性能受限于磁盘的I/O。并且,大部分情况下如果数据库是单点的话也存在单点故障问题。因此,也会有基于数据库自增的优化版方案,使用多个数据库节点,每个数据库节点的自增步长不同。
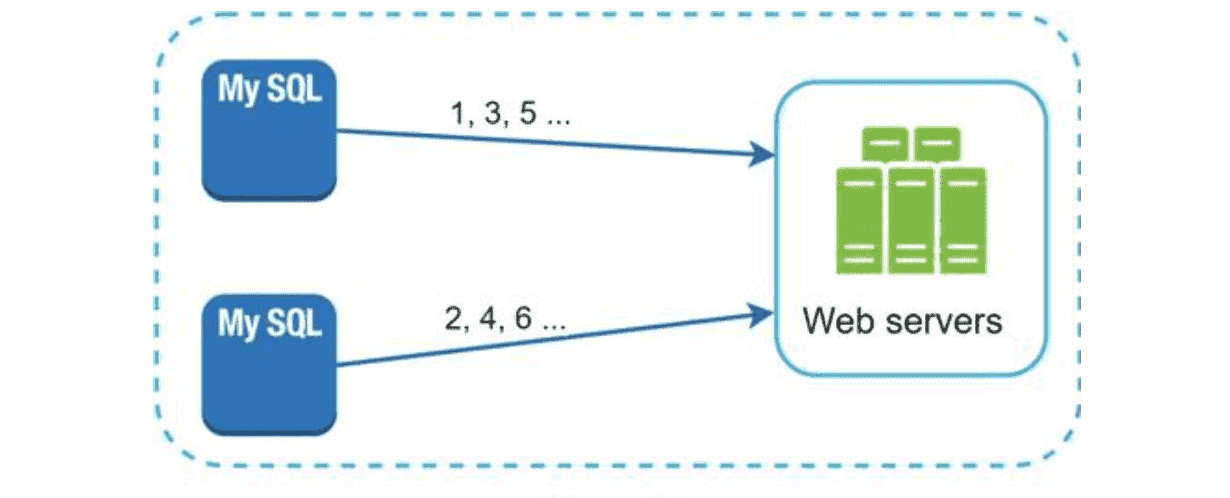
特点:
- 主键单调递增
- 生成性能受限于磁盘I/O
- 当添加/删除数据库服务器节点时,无法很好的进行扩展
- ID纯数字
Redis increment
Redis属于内存型数据库,除了数据可以持久化之外,最大的特点是数据操作都在内存中执行,读写性能非常高。并且在数据的操作中有 INCR 命令,可以进行自增操作。
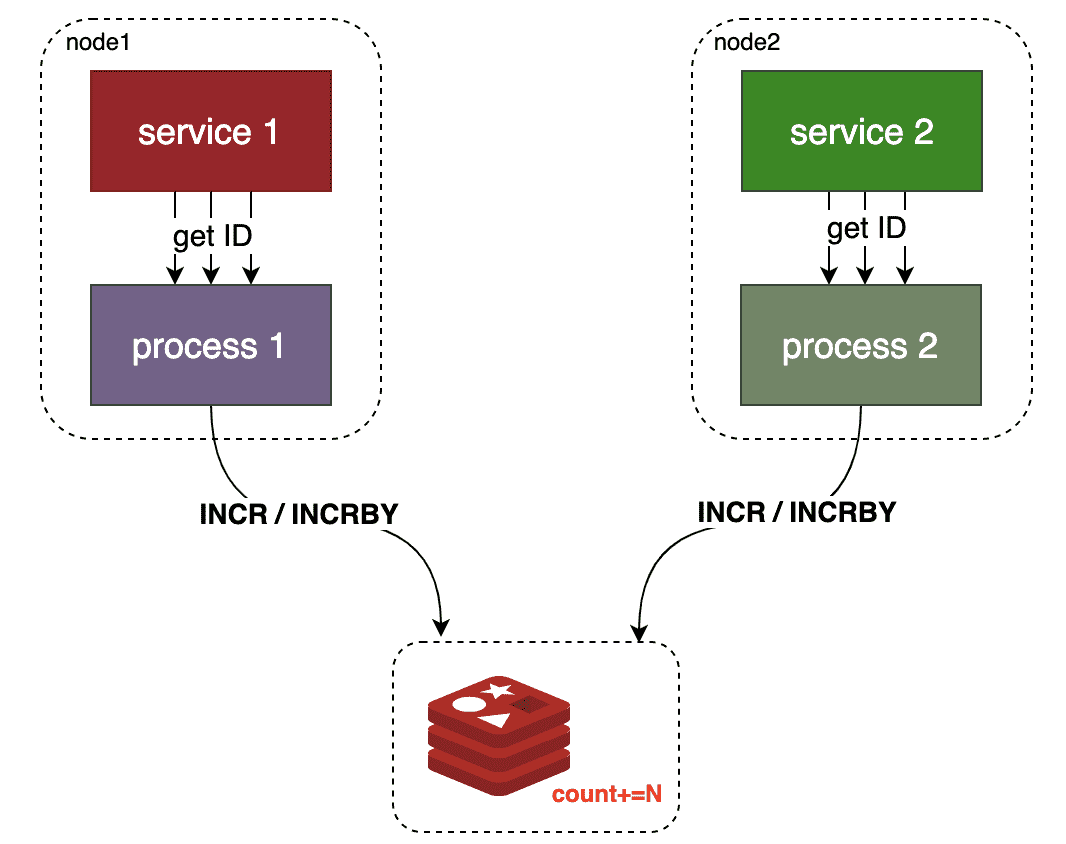
特点:
- 相比数据库来说,延迟低
- 需要额外的中间件
- ID纯数字
Database segment
众所周知,跨进程的数据操作会有大量的时间花费在网络传输、I/O操作上,非跨进程的本地内部操作效率最高。那么,Database segment便是基于此种思想的一种实现方式。
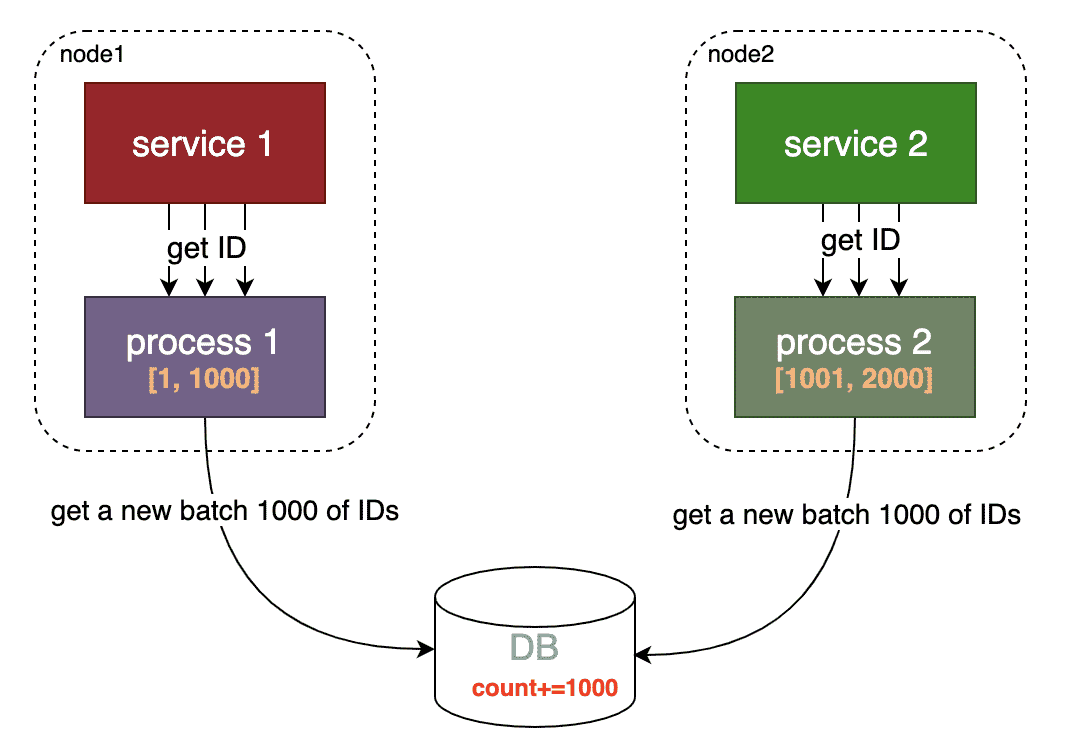
特点:
- 使用数据库为多个服务器节点保存全局ID数值(数据库也可替换为Redis或其他中间件)
- 无需多次请求外部中间件,减少网络传输、I/O操作时间消耗
- 充分利用进程本地操作的高效性
- ID纯数字
- 主流实现方式之一
一般使用方式:
- 程序在启动之后,去数据库申请一段数值空间(在原有基础上获取一段),获得之后缓存在程序内部某全局变量中。
- 进程内为需要的业务根据规则分配一个数值空间中的数值,当数值空间消耗完后,再次申请一段新的数值空间。
思考:某种情况下,整个数值空间会存在空洞。为什么?
生成布式ID的一些限制
在不同的场景下,对于分布式ID也会存在一些特有的限制,例如:订单ID只能是数字、文件ID可以是字符串等。
在设计分布式ID的生成规则以及技术方案选型时,可能需要思考是否具备以下方面:
- 是否ID必须全局唯一
- 是否ID只能是数字
- 是否ID必须是 64 bit
- 是否ID根据时间有序
- 是否ID每秒钟必须生成数量达到某个量级
- 是否ID需要针对安全性做一些特殊处理(例如:不能通过ID推测出今天的订单数量)
不同的场景,可以选择不同的实现方式或者对多种实现方式进行组合。总之,适合的才是最好的。
Go源码中 goid 的生成原理
对于阅读过go内核源码或者熟知GMP模型的人来说,可能都会知道每个goroutine都会存在一个不可导出的字段goid,用来标识当前goroutine这个资源。goid的生成原理又是怎么样的呢?一起通过源码来追溯一下吧。
对于GMP模型的原理以及交互逻辑,这里不再进行讲解,可以查阅相关资料。
1 | package runtime |
在go代码中每次调用 go func(){} 类似的代码时,都会生成(或者复用空闲的)goroutine。
通过如下示例代码来进行验证:
1 | package main |
执行 go build -gcflags="-N -l -S" 得到如下汇编:
1 | main.main.func1 STEXT nosplit size=1 args=0x0 locals=0x0 funcid=0x0 align=0x0 |
由汇编CALL runtime.newproc(SB)可知:使用 go 关键字的确会调用 runtime 的 newproc 方法来生成 goroutine。
1 | package runtime |
通过 goland 在 External Libraries 中找到 runtime/proc.go 文件,在 newproc1() 方法中添加两行调试代码,打印 P 每次获取的数值域以及每个新生成goroutine获得的id值。
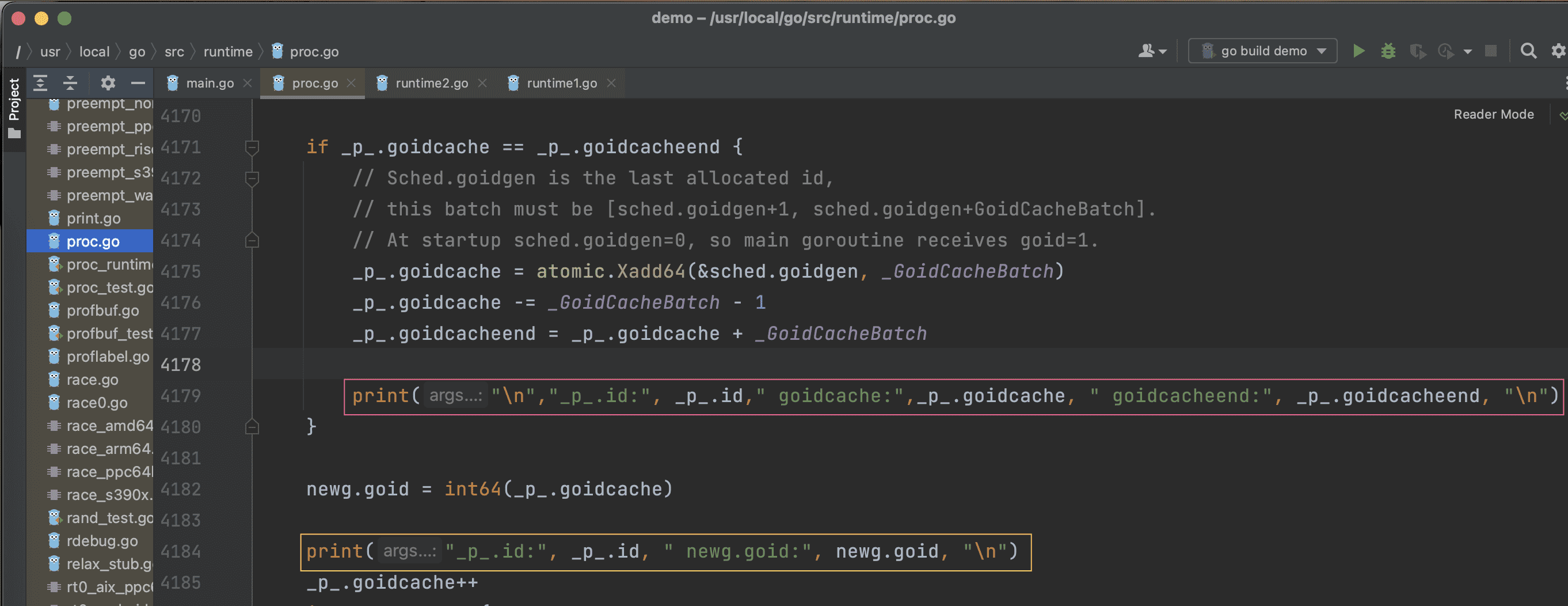
简单的示例代码:
1 | package main |
执行示例代码,得到打印结果如下所示: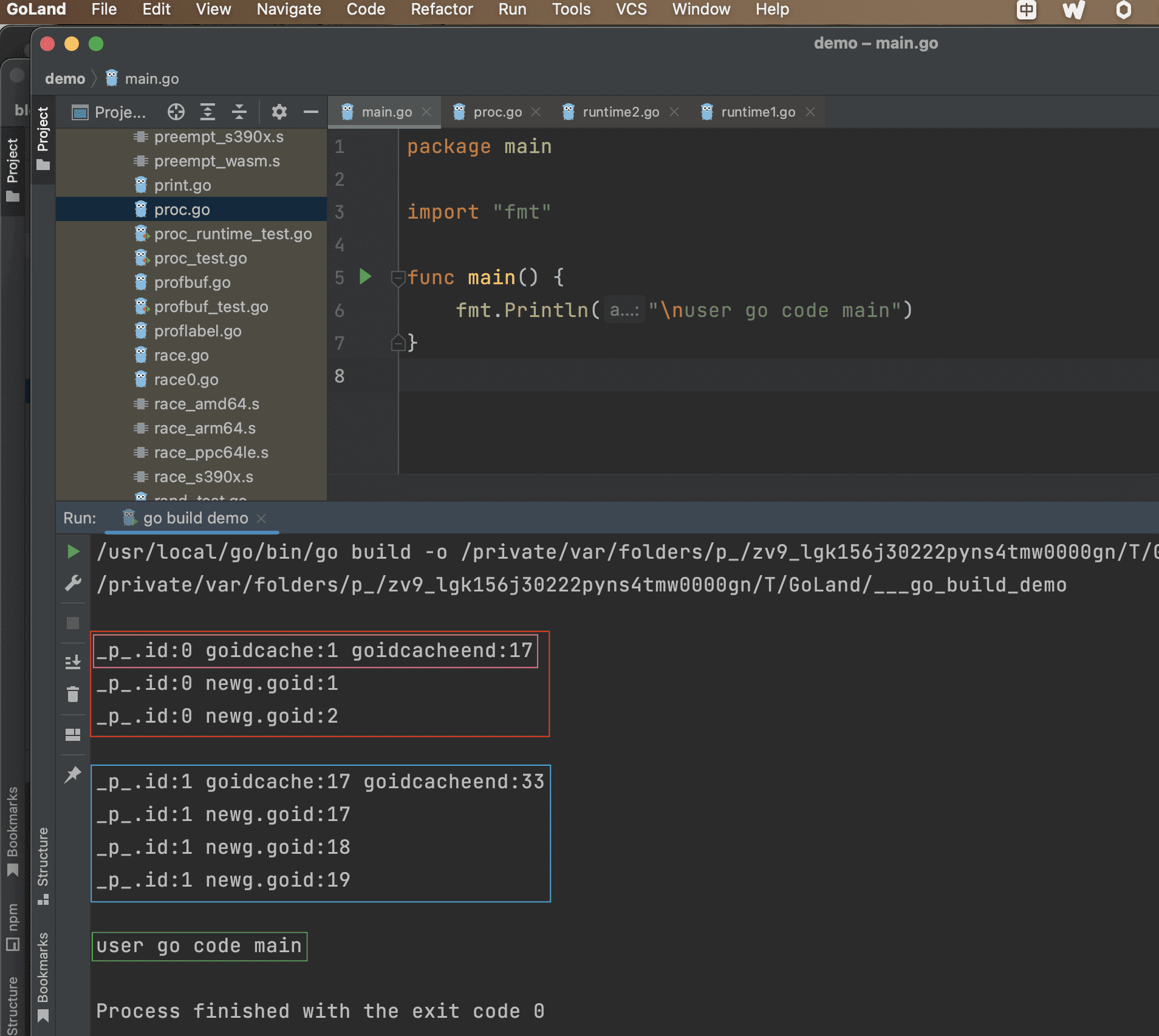
通过示例看到分别给 P0、P1 分配一次id(每次批量获取16个id),P0、P1获得的id值域如下所示:
| GMP\goidgen分配次数 | 未分配 | 第一次分配 | 第二次分配 |
|---|---|---|---|
| sched.goidgen | 0 | 0 -> 16 | 16 -> 32 |
| P0 [goidcache,goidcacheend) | [0,0) | [1,17) | - |
| P1 [goidcache,goidcacheend) | [0,0) | - | [17,33) |
由表可以看出 P 的值域符合公式:[sched.goidgen+1, sched.goidgen+GoidCacheBatch],且值域为左闭右开区间。
因此可知:初始状态 sched.goidgen 等于0,所以 main goroutine 的 goid 等于1。
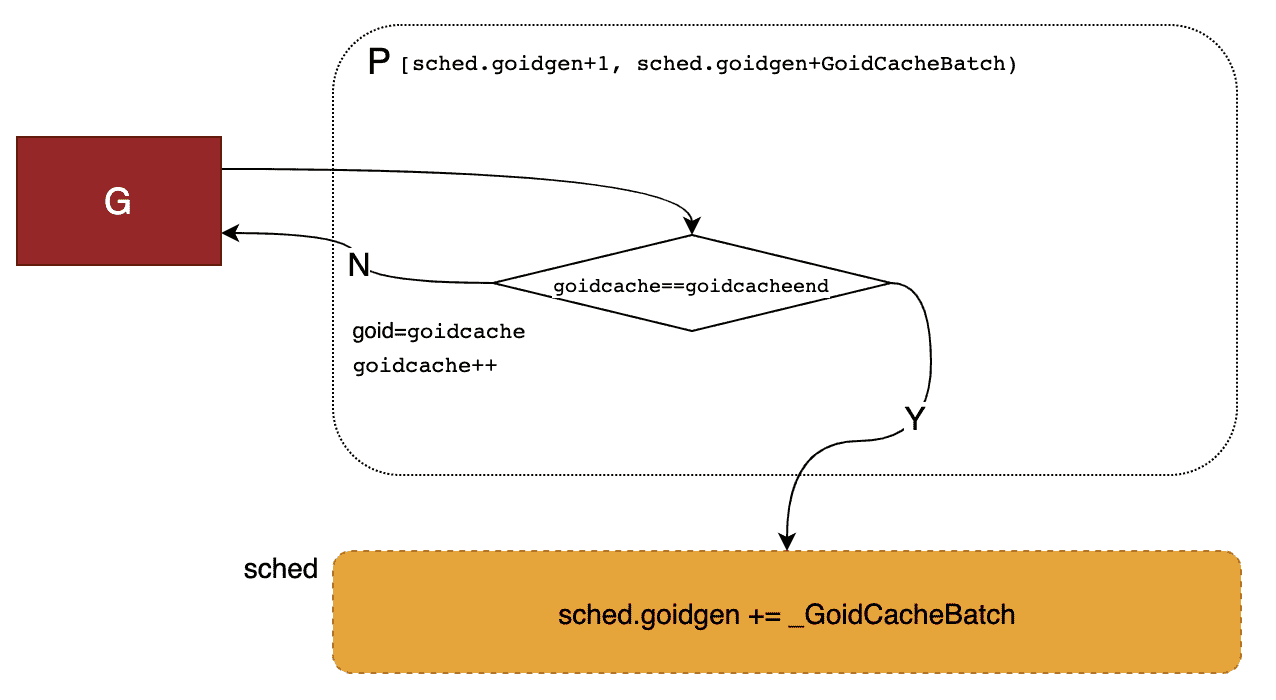
仔细回想讨论过的5种分布式ID生成方法,如果把sched.goidgen比作DB、P比作process、G比作service。那么,goid的生成逻辑是不是与Database segment的方式非常相似呢?
References
- https://www.slideshare.net/davegardnerisme/unique-id-generation-in-distributed-systems Unique ID generation in distributed systems
- https://towardsdatascience.com/ace-the-system-design-interview-distributed-id-generator-c65c6b568027 Distributed ID Generator
- https://blog.bytebytego.com/p/ep24-environment-friendly-languages Five ways to generate distributed unique ID