缓存之王 - Redis

缓存之王 - Redis
ivansli1. Redis是什么
Redis官方这样解释
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
简言之Redis(全称:Remote Dictionary Server 远程字典服务)是一个使用ANSI C编写的开源、支持网络、基于内存,并提供多种语言API的可持久化的键值对存储数据库。
2. Redis由来
2008年,意大利的一家创业公司Merzia推出了一款基于MySQL的网站实时统计系统LLOOGG,然而没过多久该公司的创始人Salvatore Sanfilippo(网名Antirez)便开始对MySQL的性能感到失望,于是他决定亲自为LLOOGG量身定做一个数据库,并于2009年开发完成,这个数据库就是Redis。
不过Salvatore Sanfilippo并不满足只将Redis用于LLOOGG这一款产品,而是希望让更多的人使用它,于是在同一年Salvatore Sanfilippo将Redis开源发布,并开始和Redis的另一名主要的代码贡献者Pieter Noordhuis一起继续着Redis的开发,直到今天。
Antirez今年已经四十多岁,依旧在孜孜不倦地写代码,为Redis的开源事业持续贡献力量。
Redis端口为什么是6379?
6379 是 “MERZ “ 九宫格输入法对应的数字。
Alessia Merz 是一位意大利舞女、女演员。Redis 作者 Antirez 早年看电视节目,觉得 Merz 在节目中的一些话愚蠢可笑,Antirez 喜欢造“梗”用于平时和朋友们交流,于是造了一个词 “MERZ”,形容愚蠢,与 “stupid” 含义相同。
后来 Antirez 重新定义了 “MERZ” ,形容”具有很高的技术价值,包含技艺、耐心和劳动,但仍然保持简单本质“。
到了给 Redis 选择一个数字作为默认端口号时,Antirez 没有多想,把 “MERZ” 在手机键盘上对应的数字 6379 拿来用了。

3. Redis为什么快?
完全基于内存,绝大部分请求是纯粹的内存操作,非常快速
数据结构简单(数据结构是专门设计的),对数据操作也简单
采用单线程(6.x之前),避免了不必要的上下文切换和竞争条件
不存在多进程/线程切换消耗 CPU
不存在加锁/释放锁操作,没有因为可能出现死锁而导致的性能消耗
非阻塞I/O多路复用模型
4. RESP协议
RESP全称:REdis Serialization Protocol
- 实现简单
- 快速解析
- 可读性强
Redis协议将传输的结构数据分为5种最小单元类型,单元结束时统一加上回车换行符号\r\n。
- 单行字符串 以 + 符号开头。
- 多行字符串 以 $ 符号开头,后跟字符串长度。
- 整数值 以 : 符号开头,后跟整数的字符串形式。
- 错误消息 以 - 符号开头。
- 数组 以 * 号开头,后跟数组的长度。
- 单行字符串 hello world
+hello world\r\n - 多行字符串 hello world
$11\r\nhello world\r\n
多行字符串当然也可以表示单行字符串。 - 整数 1024
:1024\r\n - 错误 参数类型错误
-WRONGTYPE Operation against a key holding the wrong kind of value\r\n - 数组 [1,2,3]
*3\r\n:1\r\n:2\r\n:3\r\n - NULL 用多行字符串表示,不过长度要写成-1。
$-1\r\n - 空串 用多行字符串表示,长度填 0。
$0\r\n\r\n
注意这里有两个\r\n。为什么是两个?因为两个\r\n之间,隔的是空串.
5. 丰富的数据类型
常用的几种数据类型
- string
- list
- set
- zset
- hash
- HyperLogLog
- bitmap
- Geo
6. 数据过期淘汰策略
- 懒性删除
触发机制
当访问redis中键值对时会判断这个键值对是否过期,如果过期的话就会删除这个键值对并返回nil
优点:对CPU友好,不用执行与当前命令无关的操作
缺点:对内存不友好,当大量过期的键值对不被访问时会浪费大量内存空间
- 定期删除
为了弥补惰性删除对于内存的不友好,redis中还有一种过期策略即定期删除。
- 触发机制
当一个键值对设置expire后,redis中会维护一个过期字典。这个过期字典在redis中会使用serverCron时间事件轮询,轮询过期键值对进行释放。(redis.conf配置文件中hz配置项配置,serverCron每秒执行次数, 默认10表示每100ms执行一次serverCron)
redis中限制每次过期key清理时间不超过CPU时间的25%,这段时间内会执行如下步骤操作:
I. 随机选取过期字典中的100个key
II. 淘汰所有的过期key
III. 如果过期key超过25个则重复步骤1
- 主动删除
物理机的内存空间是有限的,当所有内存被占满以后redis接收到写操作命令应该怎么处理?此时就会触发主动删除
触发机制
redis.conf配置文件中maxmemory参数设置redis占用内存的大小,当超过这个值限定以后将会根据maxmemory-policy设置清理redis内存对象
有关这个maxmemory提醒一点:集群环境下适当调低maxmemory配置,给output buffer预留空间。因为output buffer空间并不包括在maxmemory中
清理策略
清理策略划分可以分为两个维度与三个方面两个维度分别是过期键中筛选、所有键中筛选三个方面分别是 lru、ttl、random
- volatile-lru:过期键中最长时间未调用的键值对
- volatile-ttl:过期键中即将过期的键值对
- volatile-random:过期键中随机删除
- allkeys-lru:所有键中最长时间未调用的键值对
- allkeys-random:所有键中随机删除
- noevication:不清理,返回异常
7. 持久化
目前,分为3种持久化方式
- RDB
- AOF
- 混合模式(RDB+AOF)
RDB(Redis DataBase)
- 开启方式
redis.conf配置save
1 | # save "" # 关闭RDB |
功能核心函数:rdbSave() / rdbLoad()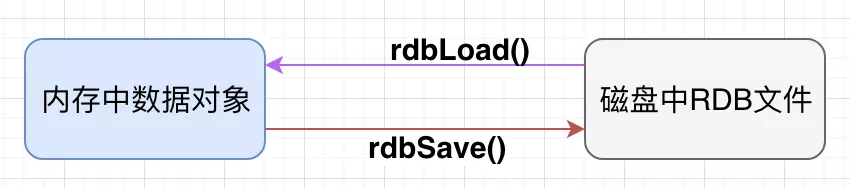
- RDB触发场景:
- 执行 SHUTDOWN 命令(未配置AOF)
1 | 127.0.0.1:6379> shutdown |
- 执行 SAVE/BGSAVE 命令
1 | 127.0.0.1:6379> BGSAVE |
SAVE/BGSAVE区别
SAVE :使用主进程进行RDB快照数据的持久化(会阻塞Redis其他操作)
BGSAVE :fork()出子进程进行RDB快照数据的持久化(推荐)
优点:
1.RDB是一个非常紧凑的文件,保存了Redis在某个时间点上的数据集,非常适合用于进行备份
2.RDB在恢复大数据集时的速度比 AOF 的恢复速度要快
缺点:
1.数据集比较庞大时,fork()可能会非常耗时,造成服务器在某段时间内停止处理客户端
2.每隔一段时间才保存一次RDB文件,在这种情况下,一旦发生故障停机,你就可能会丢失好这段时间的数据
AOF(Append-only file)
- 开启方式
redis.conf配置
1 |
|
核心函数:flushAppendOnlyFile()
每当执行服务器(定时)任务或者函数时flushAppendOnlyFile函数都会被调用,这个函数执行以下两个工作
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中
优点:
1.如不小心执行flushall命令, 只要AOF文件未被重写,停止服务器, 移除AOF文件末尾的FLUSHALL命令并重启Redis,就可以将数据集恢复到flushall执行之前的状态
2.可读性高
3.默认为每秒钟fsync一次,也最多只会丢失一秒钟的数据
缺点:
1.AOF文件比较大
2.加载入内存,耗时比RDB慢
混合模式
- 开启方式
1 | # When rewriting the AOF file, Redis is able to use an RDB preamble in the |
- 显式的查看混合模式的数据
- 执行BGREWRITEAOF命令
1 | ➜ software redis-cli |
- 查看appendonly.aof文件
1 | REDIS0009� redis-ver5.0.7� |
混合模式的AOF文件数据,相当于:
某刻的RDB格式全量数据 + 此刻之后的RESP格式增量数据
为什么使用混合模式(RDB优点+AOF优点):
- RDB格式数据加载快速
- AOF追加的RESP数据,可以减少数据的丢失
- 既能保证Redis重启时的速度,又能减低数据丢失的风险
重启之后数据加载
源码(V5.08)追踪
server.cmain() -> loadDataFromDisk()
1 | /* Function called at startup to load RDB or AOF file in memory. */ |
判断是否开启了AOF
- 是:则通过loadAppendOnlyFile() 加载AOF文件
- 否:通过rdbLoad() 加载RDB文件
loadAppendOnlyFile()
1 | /* Replay the append log file. On success C_OK is returned. On non fatal |
通过读取AOF文件的前5个字符来判断是否是RDB+AOF混合模式
- 是:则先加载RDB数据(二进制数据),再一条一条的加载AOF数据(RESP协议格式数据)
- 否:一条一条的加载AOF数据(RESP协议格式数据)
大致的重启数据加载流程为: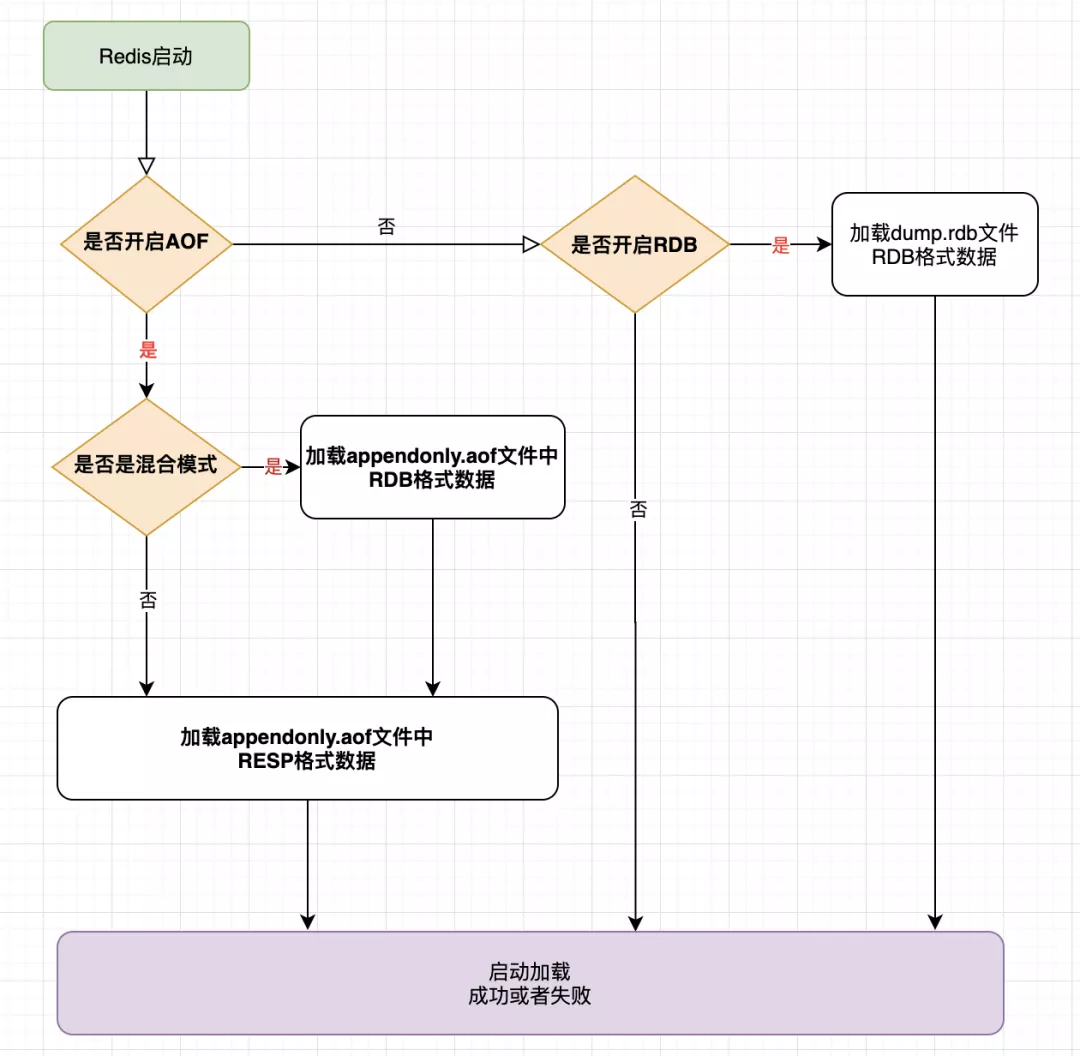
小结
至于Redis为什么是最流行的键值对存储数据库,仁者见仁智者见智。
个人认为,总结几点:
- 是开源的(节约企业自研成本)
- 数据类型丰富(不仅仅是单纯的k-v)
- 处理速度快(单机读写10W+左右)
- 支持数据持久化
- 多种语言API支持
附:
曾有一同事在追溯Redis源码之后,评价道“这是我看过最舒服的源码”。
源码注释详细不说,各种变量、函数名称也是十分标准。
由此可见一斑